De Grote Coronastudie: een kadering van statistische resultaten
Introductie
De eerste editie van de Grote Coronastudie dateert van 17 maart 2020. Na een initiële fase van 11 wekelijkse edities, werd er na 2 juni 2020 overgeschakeld naar tweewekelijkse edities. Op 6 april 2021 vond de 34e editie plaats. Gedurende het laatste jaar zijn veel resultaten van de studie gedeeld met beleidsmakers en het grote publiek, via onze websites (http://www.corona-studie.be, https://corona-studie.shinyapps.io/corona-studie/ en https://blog.uantwerpen.be/corona/blog/) en de pers. In onze rapporten, persberichten en toelichtingen trachten we resultaten correct en voldoende genuanceerd te verwoorden, doch deze nuances worden niet altijd overgenomen in communicatie door derden. We halen daarom in deze tekst enkele algemene sterktes en zwaktes aan. Verdere informatie kan gevonden worden in de literatuur, o.a. in de klassiekers over survey design van Foreman (1991) of Kish (1965), het werk van Korn & Graubard (1999) over het opzet van gezondheidsenquêtes, en Callegaro et al. (2015) over web survey design.
De Grote Coronastudie: een niet-probabilistische observationele online survey
Een bevraging van de bevolking kan gebeuren via een census of een survey. Een census tracht gegevens te verzamelen over elk individu in de bevolking (of technischer, de populatie, zoals we later zullen beschrijven). Een census uitvoeren duurt lang en kost veel geld en menskracht. Vandaar wordt het gros van wetenschappelijke bevragingen gedaan via surveys; hierin bevraagt men een subset van de populatie en worden statistische methoden gebruikt om via die subset uitspraken te doen over de populatie. De Grote Coronastudie is een survey. Ze is speciaal vanwege haar online aard en gegevensverzameling via zelfrapportage, maar ze behoort zoals alle surveys tot de brede verzameling van de empirische studies, die kunnen ingedeeld worden volgens drie grote assen: (1) probabilistische versus niet-probabilistische studies; (2) experimentele versus observationele studies; (3) samenvattende versus comparatieve studies. De meeste studies maken een keuze op elke van deze drie assen.
As 1: probabilistische versus niet-probabilistische studies
Er wordt een onderscheid gemaakt tussen probabilistische en niet-probabilistische studies. In een probabilistische studie zal elke deelnemer door de onderzoeker(s) uitgenodigd worden. De selectie van deelnemers uit de populatie (in feite uit het steekproefkader, zoals later duidelijk zal worden) wordt via een willekeurige steekproef gedaan, dus via een kans die tussen 0 en 1 ligt (inclusief de waardes 0 en 1). Die willekeurige steekproef kan een systematische component bevatten, zodat onderzoekers een willekeurige steekproef kunnen nemen die optimaal is voor een onderzoeksvraag (bv. 50 rokers en 50 niet-rokers worden geselecteerd in een studie naar het effect van roken op bloeddruk). De inzichten van een studie kunnen immers vertekend worden door een steekproef waarvan bepaalde karakteristieken niet gebalanceerd zijn; we komen later uitvoerig terug op vormen van vertekening. In niet-probabilistische studies neemt een deelnemer zelf het initiatief om deel te nemen. De onderzoeker komt hier niet tussen. In een niet-probabilistische studie kan men sneller zeer grote steekproeven bekomen, maar die zijn meestal geen willekeurige subset van de populatie (bv. er doen disproportioneel weinig jonge mannen uit Brussel mee aan de studie). Hier zal dus een correctie voor afwijkende karakteristieken (zoals leeftijd, geslacht, enz.) in de steekproef tegenover de populatie nodig zijn. Merk op dat een willekeurig getrokken steekproef niet vrij is van problemen; immers, potentiële respondenten kunnen hun medewerking verlenen of weigeren.
As 2: experimentele versus observationele studies
In een experimentele studie worden de deelnemers door onderzoekers blootgesteld aan één of meerdere interventies en, waar nodig, op een volstrekt willekeurige manier over groepen verdeeld. Een kwaliteitsvol uitgevoerde experimentele studie vormt de gouden standaard, omdat onderzoeksomstandigheden gecontroleerd kunnen worden. Bijvoorbeeld, de leeftijds- en geslachtsverdeling in de placebo- en vaccin-groepen in een vaccinatiestudie zijn ongeveer gelijk. Maar het opzetten van experimentele studies kost tijd en resulteert meestal in steekproeven met een beperkte omvang, tenzij bij grote en dus zeer dure studies. In een vaccinatiestudie is een hoge kostprijs om ethische, maatschappelijke en economische redenen verantwoord.
In een observationele studie bepalen onderzoekers de blootstelling niet. Dit type van studie wordt vaak toegepast wanneer een potentieel schadelijk effect wordt onderzocht, zoals het effect van het dragen van een veiligheidsgordel op de overlevingskans bij een auto-ongeval. Hier wordt uiteraard niet mee geëxperimenteerd, tenzij bijvoorbeeld met dummy’s; men maakt eerder gebruikt van reeds bestaande registraties van ongevallen. Wie deelneemt kan zowel bepaald worden door de onderzoekers (probabilistisch, bv. op basis van bestaande registratiesystemen van ongevallen die reeds hebben plaatsgehad) als door de respondenten (niet-probabilistisch, bv. bij een open online survey).
Kortom, vaak vormen observationele designs de enige manier om onderzoeksvragen te beantwoorden, omdat een experimentele setting onmogelijk te handhaven is. De opzetprocedure van observationele studies verloopt meestal ook snel en kosteneffectief en resulteert vaak in grotere steekproeven dan experimentele studies. Anderzijds wordt het vaak moeilijker om uitspraken te doen over mogelijke verbanden, omdat de groepen die men vergelijkt ook in andere zaken kunnen verschillen dan in de conditie die men onderzoekt. Bijvoorbeeld, leeftijd en geslacht van mensen die een veiligheidsgordel dragen, kunnen gemiddeld verschillen van de andere groep, maar leeftijd en geslacht zijn mogelijk zelf geassocieerd met de overlevingskans bij een auto-ongeval. Men dient dan voor dergelijke factoren te corrigeren, zoals dat heet, om de associatie tussen het dragen van een veiligheidsgordel en de overlevingskans correct te kwantificeren.
Surveys zijn van nature observationeel, maar men kan nog steeds een onderscheid maken tussen willekeurig getrokken steekproeven (probabilistische studie), bijvoorbeeld uit het bevolkingsregister, die dan representatief zijn voor de bevolking (cf. de Belgische Gezondheidsenquête), of een steekproef die ontstaat doordat mensen spontaan beslissen om deel te nemen (niet-probabilistische studie).
As 3: samenvattende versus comparatieve studies
Samenvattende studies worden opgezet om een beeld te krijgen van een welgedefinieerde populatie. We trachten dan vaak om een samenvattende maat te verkrijgen, zoals “Wat is de gemiddelde perceptie over de lockdown bij mannen en vrouwen?”. In comparatieve studies willen we vergelijkingen doen, zoals “Verschilt de perceptie over de lockdown tussen mannen en vrouwen?”. We komen hier later in deze tekst uitvoeriger op terug.
Zoals eerder vermeld, maken de meeste studies een keuze op elk van de drie assen. Een klinische studie, zoals een vaccinatiestudie, is meestal probabilistisch, experimenteel, en comparatief: deelnemers worden geselecteerd (probabilistisch) en willekeurig toegewezen aan de behandelings- of placebogroep (experimenteel), waarbij het doel van deze studie een vergelijking tussen de behandelings- en placebogroep behelst (comparatief). Merk op dat deelnemers vaak worden gerekruteerd via een oproep. Men kan dus interesse tonen om deel te nemen. Maar dit betekent niet dat al deze mensen sowieso zullen deelnemen, zoals het geval zou zijn in een niet-probabilistische studie. Integendeel, uit de set van mogelijke geïnteresseerden kiezen de onderzoekers probabilistisch een subset. Een ander voorbeeld: een studie naar de effecten van roken op longkanker kan al of niet probabilistisch zijn, is zeker niet experimenteel (want dat zou niet ethisch zijn), dus observationeel, en comparatief.
De Grote Coronastudie is een niet-probabilistische survey, omdat iedereen zelf het initiatief kan nemen om al of niet deel te nemen; wanneer iemand beslist om deel te nemen, maakt zijn/haar deelname deel uit van de dataset, zonder inmenging van de onderzoekers. Ze is observationeel omdat er geen enkele interventie plaatsheeft op initiatief van de onderzoekers. Tenslotte zijn er zowel samenvattende (bv. “Welke fractie van de bevolking draagt altijd een mondmasker in de openbare ruimte?”) als comparatieve (bv. “Is er een verschil tussen mondmaskergewoonten bij mannen en vrouwen?”) doelstellingen. Het observationele, niet-probabilistische survey design vormt een interessante tool om de pandemie in al haar aspecten te monitoren, omdat het belangrijk is om op een snelle manier veel mensen te bereiken, en snel signalen te kunnen oppikken. We maken handig gebruik van het internet, omdat dit het uitgelezen medium is om snel veel deelnemers te rekruteren. Er rijzen dan wel vragen over wie deelneemt aan de studie en hoe je voor mogelijke vertekening kan corrigeren. Hiervoor onderscheiden we twee vragen: (1) Wie bereiken we met de studie?; (2) Wie van de mensen die bereikt worden, vult de studie in?
Wie wordt bereikt in een online survey?
De Grote Coronastudie betreft een studie in de vorm van een survey, met Belgische bevolking als geografisch bepaalde populatie waarover we uitspraken willen doen. Het steekproefkader is de groep van mensen uit de populatie die we in theorie kunnen bereiken, of in technische termen, alle mensen in de populatie waarvoor de kans om in de steekproef te belanden groter is dan 0.
Idealiter komen de populatie en het steekproefkader exact overeen. In de praktijk is dit meestal niet zo. Bij rekrutering via telefoon kunnen enkel mensen bereikt worden die een telefoon hebben. Bij een onlinestudie, zoals de onze, kunnen in theorie enkel mensen met toegang tot een internetverbinding deelnemen. Meestal zijn deze tendensen geassocieerd met bv. socio-economische status of leeftijd, met als gevolg dat het steekproefkader bepaalde leden van de populatie uitsluit. Dat hoeft op zich geen probleem te zijn. We moeten echter wel opletten wanneer datgene dat we willen onderzoeken ook geassocieerd is met socio-economische status of leeftijd, want vertekening kan dan ontstaan; later meer hierover.
Nemen we dus als steekproefkader mensen die toegang hebben tot het internet. Er zijn dan nog andere onvoldoende begrepen dynamieken, zoals de associatie tussen de tijd die iemand online spendeert en de kans dat deze persoon de studie zal opmerken, die ervoor zorgen dat niet elk individu in de bevolking even goed kan bereikt worden. Wanneer deze kans om iemand te bereiken geassocieerd is met karakteristieken van mensen die ook informatief zijn voor een onderzoekvraag, kan er vertekening van resultaten ontstaan wanneer we hier niet voor corrigeren. Deze vertekening, ook diegene die ontstaat door een suboptimaal steekproefkader, wordt selection bias genoemd.
De Grote Coronastudie werkt via een open call en is beschikbaar in vier talen (Nederlands, Frans, Duits, Engels). Er zijn via cookies controles voor dubbele deelname voorzien. Oproepen worden gedaan via verschillende zeer breed geconsulteerde media (bv. VRT, HLN, VTM, Facebook, Twitter). We maken op sociale media sinds februari 2021 gebruik van betaalde reclame om deelnemers rekruteren. We richten die niet op specifieke groepen in de bevolking. Elke editie wordt opengesteld voor iedereen, ongeacht of men al eens deelnam. We geven deelnemers de mogelijkheid om hun e-mailadres achter te laten, zodat ze een notificatie krijgen van een volgende editie. Merk op dat de e-mailadressen niet verbonden worden met de verkregen gegevens uit specifieke deelnames. Studieresultaten verschijnen ook frequent in de media, zowel via openbare omroepen van radio en televisie als via privé-omroepen, evenals in de geschreven pers, wat het aantal mensen dat bewust weet heeft van deze studie groot maakt.
Wie neemt deel aan een online survey?
De mensen uit het steekproefkader die we bereiken, vormen nog niet de uiteindelijke steekproef. Mensen die weet hebben van de studie kunnen namelijk zelf bepalen of ze deelnemen. Dit resulteert meestal in een steekproef waarvan de deelnemers geen willekeurige subset vormen van de mensen die we bereiken. Er kunnen verschillende redenen zijn waarom iemand niet, of slechts deels, deelneemt: bv. de persoon heeft geen tijd, heeft geen laptop of smartphone ter beschikking op het moment van de studie, is niet zo geïnteresseerd in de coronacrisis, enz. Dit resulteert dan in een opportunistische steekproef (in tegenstelling tot een willekeurige steekproef). Wanneer er daardoor trends ontstaan omdat mensen met bepaalde profielen meer of minder geneigd zijn om deel te nemen dan anderen, kan er volunteer bias ontstaan. Wanneer bepaalde profielen meer geneigd zijn om de studie in haar volledigheid in te vullen dan anderen, is er mogelijks attrition bias. Wanneer er trends zijn in het opnieuw deelnemen na een eerdere deelname, kan retention bias voorkomen. In een online survey via zelfrapportage kan een opportunistische steekproef ook dynamieken vertonen in de grondigheid waarmee deelnemers de vragen invullen. Om dit laatste probleem tegen te gaan, kiezen we er daarom bij het gros van onze vragen voor dat deelnemers een antwoord moeten geven om verder te kunnen gaan naar de volgende vraag.
Hoe corrigeren we voor gelimiteerde representativiteit?
Het feit dat een online survey zoals de Grote Coronastudie te maken krijgt met dynamieken in wie er wordt bereikt en wie van die mensen beslist om deel te nemen aan de studie, spreken we van een steekproef die niet representatief is voor de populatie, zijnde de hele Belgische bevolking. Merk op dat het vaak vanuit de gegevens moeilijk te besluiten valt of vertekening voortvloeit uit selection bias of de mogelijke vormen van bias die eerder gerelateerd zijn aan opportunistische deelname nadat iemand werd bereikt.
De mate waarin we kunnen corrigeren voor vertekening hangt af van de informatie die voorhanden is. We onderscheiden drie scenario’s. Scenario 1: we bevragen persoonlijke karakteristieken waarvan we een vermoeden hebben dat ze geassocieerd zijn met de vertekening en we hebben informatie over deze kenmerken in de algemene bevolking, zodat we een correctie kunnen toepassen; scenario 2: we hebben een vermoeden over deze persoonlijke kenmerken en we bevragen ze in de survey, maar we hebben geen informatie over deze kenmerken in de algemene bevolking; scenario 3: we kennen de karakteristieken die geassocieerd kunnen zijn met vertekening niet of we kunnen ze niet bevragen.
We richten ons hier terug op samenvattende en comparatieve studies. Niet-representatieve steekproeven hebben een mogelijk effect op beide types van analyses, maar in de meeste gevallen zijn de effecten ervan het aanzienlijkst in de analyse van een samenvattende studie. Immers, een samenvatting is gericht op een representatief beeld van belangrijke aspecten van de populatie.
Samenvattende statistische analyse
In dit soort analyse kunnen we gedeeltelijk corrigeren voor vertekening, vaak gebruik makend van herwegingen van verzamelde gegevens. Of je een herweging kan doen, hangt af van welke informatie je voorhanden hebt. Stel dat we ons in “scenario 1” (zoals hierboven beschreven) bevinden; we hebben 10 deelnemers, waarvan 7 vrouwen en 3 mannen. We stellen de vraag: “Geef een score aan de mate waarin jij een strenge lockdown een goed idee vindt (0 = niet akkoord; 10 = helemaal akkoord)?” Gesteld dat vrouwen een hoge score geven, bv. ze kiezen allemaal 8/10. Mannen geven een lage score, bv. 4/10. Het gemiddelde geeft ons
$\frac{8+8+8+8+8+8+8+4+4+4}{10}=\frac{7 \cdot 8 + 3 \cdot 4}{10}=6.8$
We zouden besluiten dat de gemiddelde score 6.8/10 is. Maar we weten dat de Belgische bevolking voor 51% vrouwelijk is en 49% mannelijk (wat we voor beide groepen naar 50% afronden om het voorbeeld eenvoudig te houden; in de Grote Coronastudie gebruiken we uiteraard exacte proporties). Onze bovenstaande score is vertekend, omdat de genderverdeling in de steekproef niet overeenstemt met die van de populatie, terwijl gender wel geassocieerd is met de score waarin we geïnteresseerd zijn.
Inverse probability weighting (IPW) brengt een oplossing. We geven aan elke deelnemer een gewicht, waarbij mensen die ondervertegenwoordigd zijn in de studie een hoger gewicht krijgen dan zij die beter of oververtegenwoordigd zijn. We berekenen de gewichten voor het bovenstaande voorbeeld als volgt:
$gewicht_{vrouw} = \frac{proportie\ vrouwen\ in\ population}{proportie\ vrouwen\ in\ steekproef} = \frac{5/7}{7/10} = \frac{5}{7}$
$gewicht_{man} = \frac{proportie\ mannen\ in\ population}{proportie\ mannen\ in\ steekproef} = \frac{5/10}{3/10} = \frac{5}{3}$
We berekenen nu het gewogen gemiddelde
$\frac{\frac{5}{7} \cdot (8+8+8+8+8+8+8) + \frac{5}{3} \cdot (4+4+4))}{10}=\frac{\frac{5 \cdot 7 \cdot 8}{7}+\frac{5 \cdot 3 \cdot 4}{3}}{10}=\frac{5 \cdot 8+5 \cdot 4}{10}=6$
Het gewogen gemiddelde is 6/10 en is in dit voorbeeld representatief naar geslacht voor de Belgische bevolking. In de Grote Coronastudie worden, op enkele uitzonderingen na - hierover later meer - alle samenvattende statistieken gewogen via IPW voor een combinatie van geslacht, leeftijd, opleidingsniveau en provincie waarin men woont.
Zijn daarmee alle resultaten representatief voor de Belgische bevolking? Wanneer enkel geslacht, leeftijd, opleidingsniveau en residentiële provincie voor vertekening zorgen, zouden resultaten volledig representatief zijn. Maar we weten dat er wellicht meer aan de hand is, waarvoor het moeilijker is om te corrigeren. Een ander probleem is dat gewichten soms erg groot worden wanneer je een weging uitvoert voor verschillende karakteristieken tegelijkertijd. Er doen bijvoorbeeld relatief gezien erg weinig laaggeschoolde oudere mannen uit Henegouwen mee aan de Grote Coronastudie. Het gewicht van een deelnemer met een zeldzame combinatie van karakteristieken wordt dus al snel erg groot en een gewogen gemiddelde zou voor die combinatie van karakteristieken te veel bepaald worden door enkele observaties. Het haalt ook de precisie naar beneden. Dit is een reden waarom we gewichten aftoppen. Meer specifiek kan een gewicht maximaal 40 keer zo groot zijn als het kleinste gewicht in de data. Verscheidene manieren om gewichten te beperken worden besproken in Pickery (2010, Sectie 5), in een publicatie van Statistiek Vlaanderen. Hoe meer karakteristieken worden opgenomen in het berekenen van gewichten, hoe groter de kans wordt dat een combinatie van die karakteristieken leidt tot een erg groot gewicht en moet worden afgetopt. Dit is één van de redenen waarom we in onze routinematige rapporten niet voor meer karakteristieken wegen dan geslacht, leeftijd, opleidingsniveau en residentiële provincie. Deze 4 karakteristieken zijn éénduidig in hun interpretatie. Ze kunnen door alle respondenten steeds makkelijk en correct worden opgegeven. Naast de demografische en geografische karakteristieken, is opleidingsniveau een belangrijke indicator van socio-economische status, en invloedrijk voor welvaarts- en gezondheidsgerelateerde aspecten (Bilcke et al. 2017).
Soms kunnen we gewoonweg niet wegen voor een karakteristiek, omdat we er geen populatiegegevens over hebben (scenario 2). Zo is mentaal welbevinden misschien geassocieerd met de perceptie over de lockdown. We bevragen mentaal welbevinden in de Grote Coronastudie, maar we hebben hierover geen censusgegevens per provincie, geslacht, leeftijd en opleidingsniveau. We kunnen mentaal welbevinden dus niet aan de bovenstaande weging toevoegen. Ook zijn er soms karakteristieken die we niet kennen of kunnen bevragen die een rol spelen (scenario 3); hiervoor is het uiteraard niet mogelijk om te corrigeren via een weging.
Comparatieve statistische analyse
Vergelijkingen doen we via statistische modellen. In die modellen hebben niet-representatieve steekproeven meestal geringe effecten wanneer de karakteristieken die vertekening veroorzaken als zogenaamde confounders in de modellen opgenomen worden. Vergelijkingen kunnen ook gebruik maken van gewogen observaties om causale verbanden te onderzoeken, maar het zou ons te ver leiden om hier nu op in te gaan. Het team achter de Grote Coronastudie heeft via gegevens van deze survey methodologisch onderzoek uitgevoerd dat gebruik maakt van efficiënte statistische methoden om te corrigeren voor bias door opportunistische steekproeven, waarin specifiek wordt gefocust op scenario 3. We onderzoeken methoden die corrigeren voor onbekende mechanismen die ervoor zorgen dat mensen in feller getroffen gebieden gedurende de eerste coronagolf mogelijk meer geneigd waren om deel te nemen aan deze studie. Het manuscript wordt momenteel door een wetenschappelijk tijdschrift beoordeeld (Vranckx et al. 2021).
Grote steekproeven: een kanttekening
Een van de sterktes van de Grote Coronastudie is haar steekproefgrootte. Tijdens de eerste editie op 17 maart 2020 namen meer dan een half miljoen inwoners van België deel aan deze studie. Dat aantal is gradueel gedaald, maar het schommelt al maanden tussen 20,000 en 35,000 deelnemers per editie, wat nog steeds resulteert in erg veel gegevens. Merk nogmaals op dat de beschikbaarheid van veel gegevens niet altijd veel kwaliteitsvolle informatie impliceert, zoals we al aangaven in de uiteenzetting over de verschillende bronnen van vertekening, bv. door zelfrapportage. Deze bedenking wordt ook wel de Big Data Paradox genoemd (Meng 2018). We zijn hier waakzaam voor in de interpretaties van onze resultaten, wat we later in deze tekst toelichten.
Ongeacht de mogelijke vertekening door de manier waarop gegevens bekomen worden, zijn vanuit een eerder technisch oogpunt grote steekproeven van belang in de analyse. Om het intuïtief te begrijpen, denk even terug aan de samenvattende statistische analyse. Grote steekproeven laten toe om betrouwbare herwegingen te doen, want zo verkleint de kans dat een combinatie van karakteristieken niet voorkomt of zeldzaam is in de steekproef. Maar ook in de comparatieve statistische analyse spelen steekproefgroottes een belangrijke rol. We herbekijken het voorbeeld waar we aan deelnemers de volgende vraag stellen: “Geef een score aan de mate waarin jij een strenge lockdown een goed idee vindt (0 = niet akkoord; 10 = helemaal akkoord)?”. Stel dat er 5 mannen en 5 vrouwen meedoen. En stel dat de score bij mannen gemiddeld 5/10 en bij vrouwen 6/10 is. Het is moeilijk om te besluiten dat scores gemiddeld verschillen tussen mannen en vrouwen, omdat er misschien toevallig een man deelnam die een erg lage score rapporteerde en daarmee een uitschieter vormt t.o.v. het gros van de mannelijke bevolking. Maar stel nu dat er 15,000 mannen en 15,000 vrouwen deelnamen en we vinden gemiddeld resp. 5/10 vs. 6/10. In dat geval zijn we er een pak zekerder van dat dit verschil een werkelijk verschil weergeeft, omdat we conclusies kunnen trekken a.d.h.v. een grote steekproef.
Ook kunnen we het effect van vertekening hierin kaderen. Stel dat er in het vorige voorbeeld 10,000 mannen en 20,000 vrouwen meedoen. De score bij mannen is weer gemiddeld 5/10, bij vrouwen 6/10. In feite is het niet zo belangrijk voor het resultaat als deze vergelijking geen gebruik maakt van een steekproef die representatief is voor de genderbalans in de hele bevolking. Er is genoeg informatie over mannen en vrouwen om een betrouwbare vergelijking te doen. Maar stel nu dat er 10 mannen meedoen en 50 vrouwen. In dat geval gaat het onevenwicht dat verantwoordelijk is voor de niet-representativiteit hand in hand met een gebrek aan informatie om betrouwbare uitspraken te doen.
Er is een keerzijde van de medaille. Grote steekproeven zorgen ervoor dat er veel zogenaamde significante verschillen worden gedetecteerd. Wanneer bij een steekproef van 15,000 mannen en 15,000 vrouwen respectievelijk gemiddelde scores van 5.9/10 en 6/10 worden gevonden, vinden we dat dit verschil significant is, maar is dat een relevant verschil? Grote steekproeven laten toe om zeer kleine verschillen te detecteren, maar dat ontslaat ons niet van de vraag of dat verschil wetenschappelijk, maatschappelijk, klinisch, enz. relevant is. Dat doen we ook in de Grote Coronastudie: eens een verschil statistisch significant is, volgt er een reflectie of het om een relevant verschil gaat.
Cross-sectioneel vs. longitudinaal
De Grote Coronastudie verzamelt gegevens op verschillende tijdspunten. Sinds de start van de studie zijn op het moment van schrijven bijna 3 miljoen deelnames geregistreerd. Dit betreffen geen unieke individuen. Integendeel, sinds de zomer van 2020 nemen grotendeels mensen deel die al eens deelnamen. We weten dat omdat we in elke editie vragen of een participant al eens deelnam (Fig. 1).
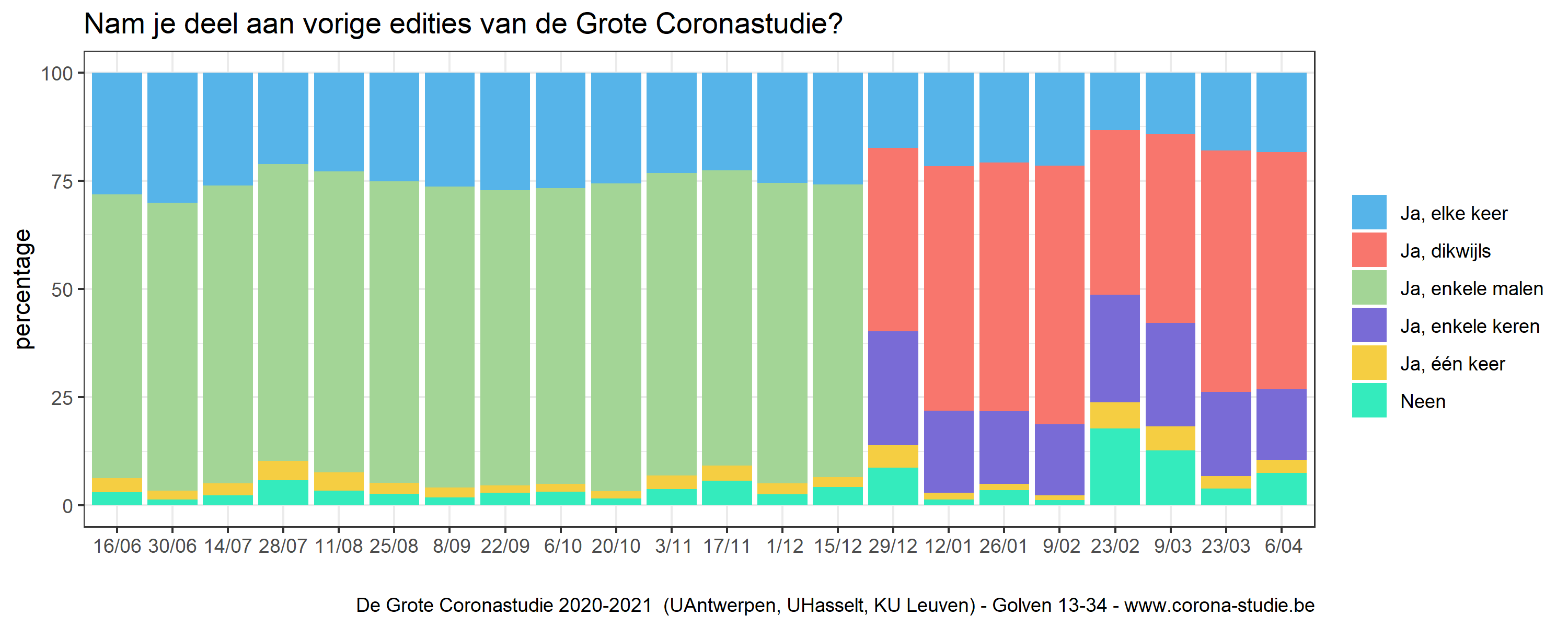 Fig. 1. Een overzicht van de antwoorden die deelnemers proportioneel gaven aan de vraag of men al eens deelnam aan een vorige editie van de Grote Coronastudie. We stelden de vraag in deze vorm vanaf 16/6/2020; voordien vroegen we dit in nog meer detail. Vanaf 29/12/2020 veranderden de antwoordopties.
Fig. 1. Een overzicht van de antwoorden die deelnemers proportioneel gaven aan de vraag of men al eens deelnam aan een vorige editie van de Grote Coronastudie. We stelden de vraag in deze vorm vanaf 16/6/2020; voordien vroegen we dit in nog meer detail. Vanaf 29/12/2020 veranderden de antwoordopties.
Om de privacy van deelnemers te vrijwaren en de drempel voor deelname zo laag mogelijk te houden, kozen we ervoor om deelname volledig anoniem te houden. We kunnen dus onmogelijk individuen linken doorheen de studie. Wel kunnen we in theorie gebruik maken van gegevens zoals geslacht, geboortejaar, residentiële woning, gezinsgrootte, enz. om een kansgebonden match te doen van deelnemers doorheen de tijd. Deze matches zijn echter nooit met zekerheid te verifiëren. Ook staan de kansgebonden matching algoritmes nog niet op punt zodat er nog veel onzekerheid is over specifieke matches.
Omwille van de bovenstaande redenen analyseren we momenteel de gegevens doorheen de tijd via een cross-sectionele analyse. Dit betekent dat je geen individuele profielen doorheen de tijd opvolgt. Wanneer gegevens doorheen de tijd worden gelinkt, zij het exact (wat hier dus niet mogelijk is) of kansgebonden, vormt dat een longitudinale studie. Er wordt momenteel onderzoek gedaan binnen het team van de Grote Coronastudie om na te gaan hoe een longitudinale aanpak binnen de context van deze studie extra informatie kan aanleveren.
Hoe trekken we besluiten?
Alle gerapporteerde samenvattende statistieken worden gecorrigeerd voor geslacht, leeftijd, opleidingsniveau en residentiële provincie. Dit is conform met de wegingen die Sciensano gebruikt in onder meer de Belgische Gezondheidsenquête en meer algemeen met de European Health Interview Survey, een initiatief dat zoveel mogelijk uniformiteit betracht tussen de gezondheidsenquêtes van de Europese lidstaten. Deze herweging verbetert de representativiteit van onze resultaten aanzienlijk. Omdat het zoals in elke studie, ongeacht of die probabilistisch of niet is, onmogelijk is om voor alle mogelijke achterliggende bronnen van vertekening te corrigeren, nuanceren we onze resultaten consistent door aan te geven dat associaties niet noodzakelijk causale verbanden impliceren en dat we vanwege natuurlijke limieten op het vlak van correctie niet alle, maar wel veel vertekening kunnen verhelpen. Wanneer we spreken over verschillen tussen mensen met verschillende karakteristieken, zijn die uitspraken gebaseerd op statistische modellen waarin gecorrigeerd wordt voor mogelijke, geobserveerde confounders. We zijn ons bewust van het verschil tussen de hoeveelheid gegevens en de omvang van de informatie die je uit die gegevens kan halen (Meng 2018) en we onderzoeken zorgvuldig welke resulterende associaties irrelevant zijn, of een mogelijk gevolg van toevallige correlaties in een niet-representatieve dataset.
Wie bereiken we met de Grote Coronastudie niet of minder goed? Wellicht ouderen, die minder frequent online aanwezig zijn; mensen die geen van de vier aangeboden talen spreken; mensen die niet bereikt worden via de verschillende mediakanalen; mensen die zich in een zwakkere socio-economische situatie bevinden; mensen die zelden op dinsdag tijd kunnen vrijmaken; of een combinatie van deze factoren. Ook niet-Vlamingen worden minder goed bereikt, ondanks pogingen om via Franstalige kanalen in Wallonië en Brussel actief mensen te rekruteren. Hierin speelt ook het feit dat de Grote Coronastudie een initiatief is van Vlaamse universiteiten, en meer aandacht krijgt in de Vlaamse dan in de Waalse pers. Veel van onze conclusies beperken we dus tot Vlaanderen of worden genuanceerd door te stellen dat er in Vlaanderen, t.o.v. andere Belgische regio’s, meer zekerheid is over deze uitspraken.
Wie van de mensen die we bereiken, besluit om niet deel te nemen aan onze studie? Daarachter ligt waarschijnlijk een complexer mechanisme dat nog niet volledig begrepen wordt. Zoals eerder aangegeven tracht lopend onderzoek uit te wijzen hoe we voor deze bronnen van vertekening zo goed mogelijk kunnen corrigeren. We onderzoeken actief welke andere factoren ons kunnen helpen om de representativiteit te kwantificeren en, indien nodig, ervoor te corrigeren. Zo hebben we recent gezien dat onze steekproeven vrij representatief zijn wat betreft de graad van volledige vaccinatie. Deels gevaccineerde personen zijn in de Grote Coronastudie sinds begin maart licht oververtegenwoordigd (Fig. 2). Dit kan deels verklaard worden door een mogelijke oververtegenwoordiging van mensen uit de zorgsector in de Grote Coronastudie. Ongeveer 14-15% van onze werkende deelnemers geeft aan in de zorgsector te werken. Dat getal komt goed overeen met de gehele werkende bevolking zoals gedocumenteerd door Statbel (15%; https://statbel.fgov.be/nl/nieuws/meer-dan-700000-werkenden-actief-de-zorg), maar die laatste includeert sociaal werkers, administratief en onderhoudspersoneel, enz., en het is niet duidelijk of die mensen in de Grote Coronastudie “zorgsector” aangeven als hun sector van tewerkstelling.
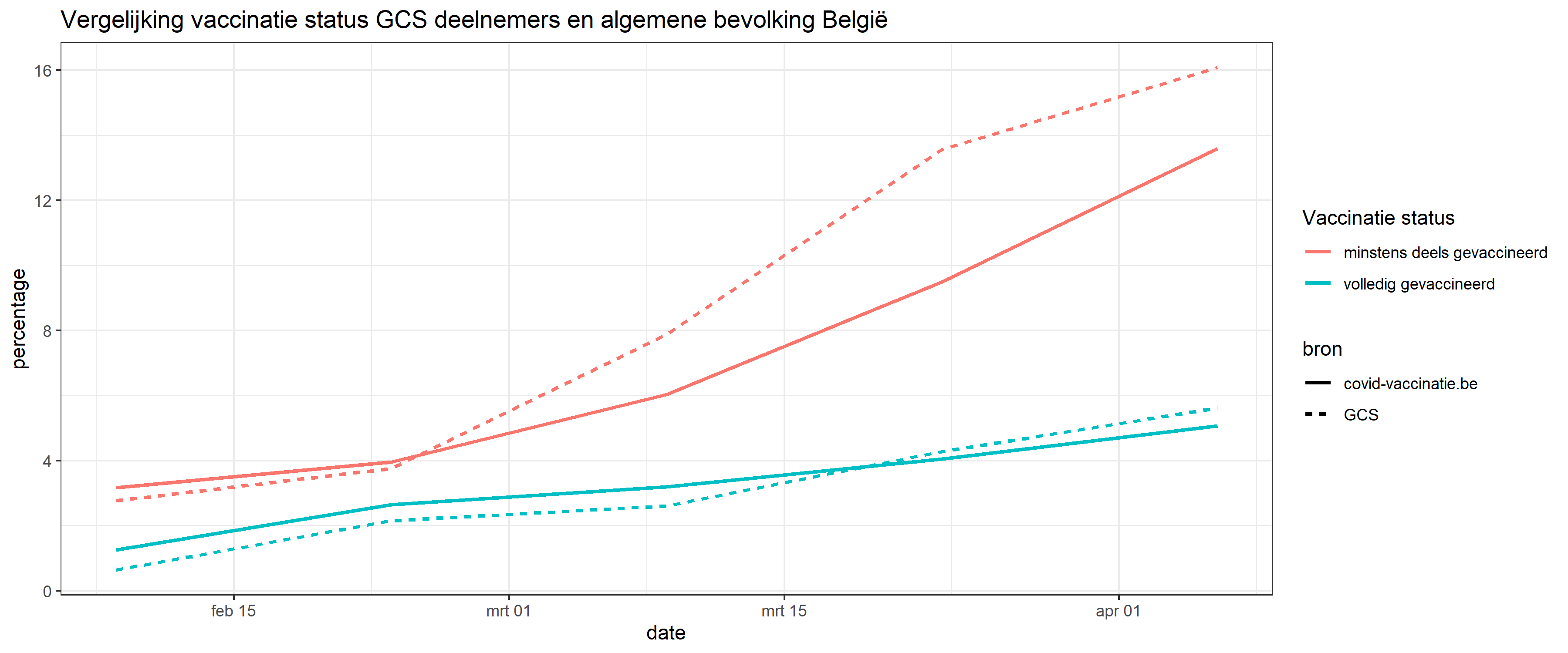 Fig. 2. Vergelijking van de vaccinatiegraad van deelnemers aan de Grote Coronastudie en de Belgische bevolking.
Fig. 2. Vergelijking van de vaccinatiegraad van deelnemers aan de Grote Coronastudie en de Belgische bevolking.
Wanneer een studie niet volledig representatief is, bevindt men zich in een suboptimale situatie, maar mits het goede gebruik van statistische methoden die hiervoor corrigeren en oplettendheid in de interpretatie van de resultaten, heeft zo’n studie het potentieel om onderzoekers tot zeer waardevolle inzichten te leiden. Een belangrijke opmerking hierbij is dat de hierboven beschreven beperkingen eigen zijn aan alle niet-probabilistische studies. Meer nog, probabilistische studies hebben te maken met gelijkaardige moeilijkheden; een panelstudie, waarbij een groep van deelnemers nauwkeurig op voorhand wordt samengesteld wat betreft karakteristieken die van belang zijn voor de onderzoeksvraag, kan worden beschouwd als een survey met een probabilistisch design. In de praktijk zal er ook hier vaak vertekening ontstaan vanwege selection bias via telefonische rekrutering, de vereiste om online vragenlijsten te willen in vullen, deelname die meestal tegen betaling gebeurt, de afwezigheid van specifieke profielen, de onvolledige kennis over de karakteristieken die voor vertekening kunnen zorgen, enz.
Er is veel onderzoek gebeurd naar de opportuniteiten en limieten van studies zoals de Grote Coronastudie en het bredere spectrum van burgerwetenschap, o.a. door leden van het team achter de Grote Coronastudie (Vandendijck et al. 2013, Neyens et al. 2019). Er is wetenschappelijke consensus dat online surveys zoals de Grote Coronastudie of de Grote Griepmeting in staat zijn om veel kwaliteitsvolle informatie te verzamelen, wanneer men in interpretaties waakzaam is over de limieten van de gegevens (bv. https://jongeacademie.be/standpunt-citizen-science/). De Grote Coronastudie is uniek omdat er, naar onze kennis, top op heden geen andere gezondheidsenquêtes in België zijn ondernomen met gelijkaardige steekproefgroottes. We zijn ervan overtuigd dat deze studie, ondanks gebruikelijke studiebeperkingen, van grote waarde is, niet enkel als gegevensbron voor de wetenschappelijke wereld, maar ook als tool die de beleidsvorming kan helpen door snel tendensen en signalen op te vangen. Door de hoeveelheid aan thema’s in de Grote Coronastudie zijn er talrijke voorbeelden van beleidsrelevante signalen die ze als eerste oppikte. Het volstaat de resultatenpagina’s van de studie erop na te slaan (https://www.uantwerpen.be/nl/projecten/coronastudie/).
Referenties
- Bilcke, J., Hens, N., and Beutels, P. (2017) Quality-of-life: a many-splendored thing? Belgian population norms and 34 potential determinants explored by beta regression. Qual. Life Res. 26: 2011–2023. DOI: 10.1007/s11136-017-1556-y
- Callegaro, M., Manfreda, K. L., and Vehovar, V. (2015) Web Survey Methodology. London: Sage Publications Ltd.
- Foreman, E. K. (1991) Survey Sampling Principles. New York: Marcel Dekker.
- Kish, L. (1965) Survey Sampling. New York: Wiley.
- Korn, E. L. and Graubard, B.I. (1999). Analysis of Health Surveys. New York: Wiley.
- Meng, X.-L. (2018) Statistical paradises and paradoxes in big data (I): law of large populations, big data paradox, and the 2016 US presidential election. Ann. Appl. Stat. 12(2): 685-726. DOI: 10.1214/18-AOAS1161SF
- Neyens, T., Diggle, P.J., Faes, C. et al. (2019) Mapping species richness using opportunistic samples: a case study on ground-floor bryophyte species richness in the Belgian province of Limburg. Sci Rep 9: 19122. DOI: 10.1038/s41598-019-55593-x
- Pickery, J. (2010) Aanmaak en gebruik van gewichten voor surveydata, met toepassing in SPSS. Statistiek Vlaanderen.
- Vandendijck, Y., Faes, C., & Hens, N. (2013) Eight years of the Great Influenza Survey to monitor influenza-like illness in Flanders. PLoS ONE 8(5): e64156. DOI: 10.1371/journal.pone.0064156
- Vranckx, M., Faes, C., Molenberghs, G., et al. (2021) A joint spatial model to analyse self-reported survey data of COVID-19 symptoms and lagged surveillance-based COVID-19 incidence data. Submitted for publication.